BY KAREN H.
Topic(s):
- Introduction to the process of webscraping, using Python and Beautiful Soup
Audience:
- People who want to understand the process for extracting data from web pages, especially in situations when direct access to the backend database might not be possible;
- People who program in Python and want to know more about the HTML parser Beautiful Soup;
- Digital humanists, scientists, infographic designers, etc..
This post appears as part of my 2016-2017 fellowship with the Metropolitan New York Library Council (METRO). My project is entitled “Interlinking Resources, Diversifying Representation: Linked Open Data in the METRO Community”. These posts document aspects of my work.
In my work to interlink resources in the METRO network surrounding the artist Martin Wong, after evaluating which institutions have resources in their collections, the first step was to gather data for those resources from each of those institutions.

The Asian American Arts Centre and artasiamerica
The Asian American Arts Centre (AAAC), founded in 1974, is a grassroots organization located in Lower Manhattan that serves to promote Asian American artists and Asian American culture. Its digital archive artasiamerica reflects the organization’s own exhibition history and the director Robert Lee’s decades-long activity of collecting materials on Asian American artists (clippings, exhibition flyers, but also artist statements, images of works, and resumes).
The content management system for artasiamerica was originally custom-built by an outside developer. Although artists continue to be added to the digital archive, currently no one on staff is responsible for maintaining the system and databases as such. In order to collect the data for my project, then, I decided the easiest method would be to simply scrape the data from the website. I should mention here that I was part of the original team to launch this particular digital archive, so when taking on this task, I was already familiar with the processing method and standards used. I knew, for example, that the Getty vocabularies ULAN (Union List of Artist Names), AAT (Art and Architecture Thesaurus), and TGN (Thesaurus of Geographic Names) were employed in describing resources, where possible, and that local terms were created when no appropriate terms were found in the Getty vocabularies.
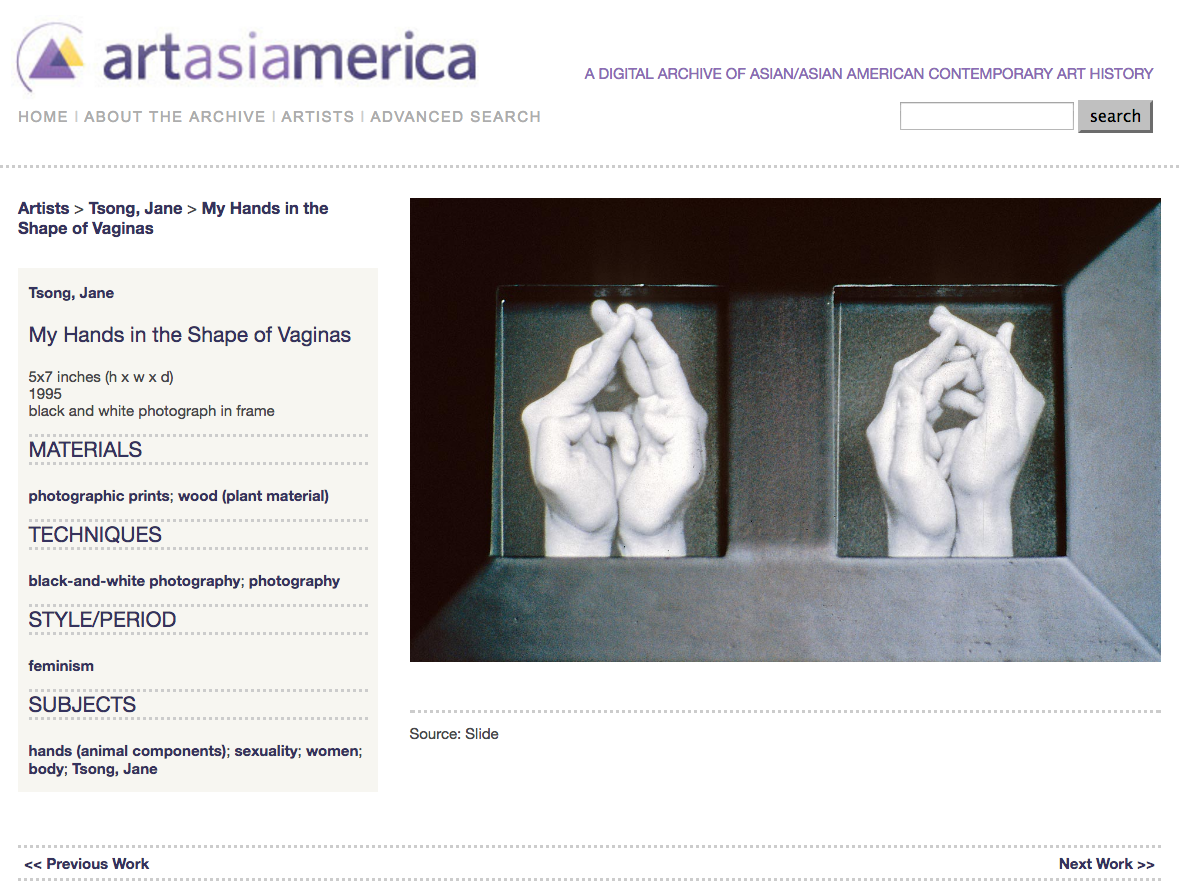
On to webscraping…
Teaching the programming language Python or how to use the Python library Beautiful Soup goes beyond the scope of this post, but I thought it might be useful to describe the process of conducting a webscrape for those familiar with Python, but not yet versed in the Beautiful Soup, or for those who want to get a sense of the process of webscraping.
Every website is different, so when conducting a webscrape, the first step should always be to find your target data and to understand how your target data fits into the overall architecture of the site. You should use the menus and the site’s other navigational tools to help you infer the architecture. More often than not, the same template is used for parallel pages. Understanding layout reuse on a site helps you write more efficient code, because looping through the same code, changing only a few variables while looping, is preferable to writing unique code for each bit of data you want to retrieve. Those repetitions in layout provide the hooks for your loops. This will be described with a specific example in the following paragraphs.
For my project, the target data for my webscrape was the metadata assigned to each of Martin Wong’s documents on the artasiamerica site. To navigate to a document, I used the main menu link “Artists” to get to an overview list of all artists with profile pages, clicked on “Wong, Martin” to get to his profile page, and then clicked on a document from the column on the right-hand side.
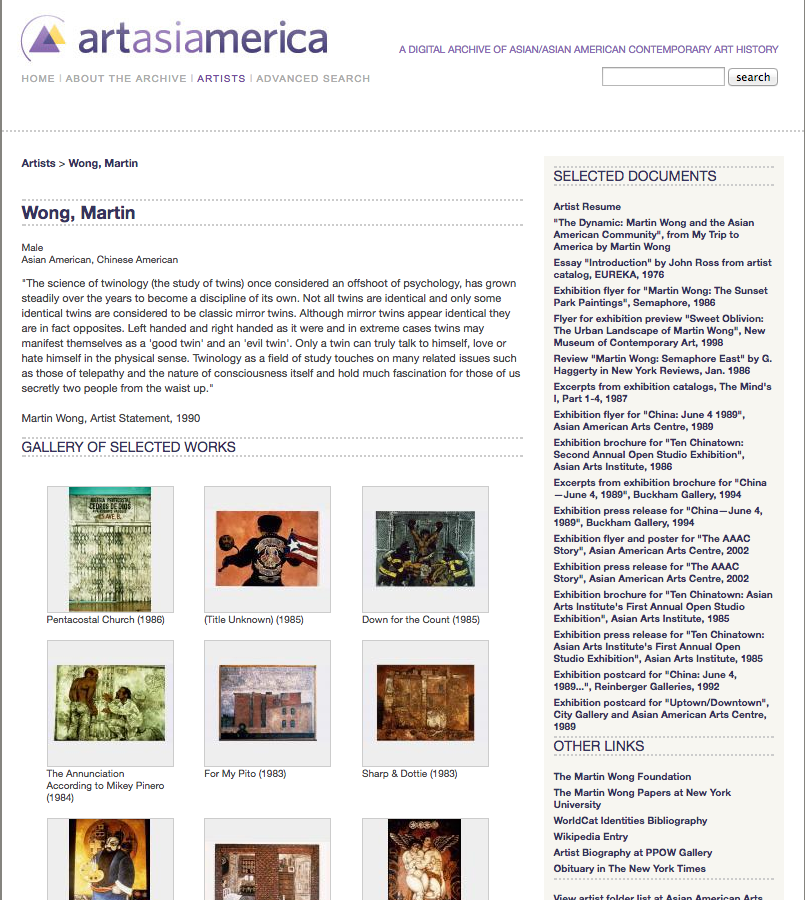
An example of a record is the exhibition brochure for “Ten Chinatown: Second Annual Open Studio Exhibition” at the Asian Arts Institute (the former name for the Asian American Arts Centre) from 1986.

If you look at another document for Martin Wong from his profile page, like the exhibition postcard for “Uptown/Downtown”, you’ll see that the layout of the page is essentially the same.
From this I know that my starting point for my scrape should be Martin Wong’s profile page, because this will act as the portal for me to get to all the documents. And I will use the same code to loop through all the documents listed. (But if I wanted instead, for example, to get ALL the documents for ALL the artists, the better starting point would have been the overview list of artists, in order to loop through each artist to loop through each document listed on the artist’s page.)
Knowing that I will start with Martin Wong’s profile page, my next step is to look at the HTML source code for that web page. On the Chrome browser, you do this by going to View>Developer>View Source. On Firefox, you do this by going to Tools>Web Developer>Page Source. For those who have never looked at HTML code before, this is basically mark-up in the form of tags (<>) that, usually in conjunction with a style sheet, tells your browser how to render different elements on a web page, everything from colors to fonts to how to lay out various sections of the page. On Wong’s profile page, I see that the documents are listed under “Selected Documents”. In the source code, then, I search for this phrase and find that it is enclosed in an <h3> tag. All the documents are then listed below this in a <ul> container, with the class “doc_list”.

I need to loop through this list enclosed by <ul>. Using the Beautiful Soup documentation to guide me, the start of my code to call the profile page and read in the source code using Beautiful Soup looks like this, where the variable ‘url’ has been defined previously as the URL of the Martin Wong profile page:
## MODULES ## import json from bs4 import BeautifulSoup import requests ## SCRIPT ## # get page wong_page = requests.get(url) # store html of artist profile page wong_html = wong_page.text # parse html as soup soup = BeautifulSoup(wong_html)
I then need to loop through the list and add each document URL to a previously declared list variable called “doc_links”. My snippet of code to do this looks like this:
# get documents list
doc_list = soup.find("ul", attrs = {"class":"doc_list"})
list_items = doc_list.find_all("li")
for list_item in list_items:
for element in list_item:
if element.name == "a":
doc_url = element.get('href')
doc_links.append(doc_url)
Next I need to look at the source code for a document. Let’s say I want the title, date, and subjects from the record. Using the above-mentioned brochure for “Ten Chinatown”, looking at the web page, I see that the title used is “Exhibition brochure for “Ten Chinatown: Second Annual Open Studio Exhibition”, Asian Arts Institute, 1986“. If I search for this in the source code for the record, I find that there is, among other instances of the title, an explicit <div> container with the class “record_title”. This is where I assume the title data is for all the documents, which I verify by looking at the source code of another document for Martin Wong. Conducting a similar search on the source code for the brochure’s date “1986”, I also discover that there is an explicit div container with the class “record_date”. From the web page, I see there are no “subjects” as such provided, but keywords. I search for the word “keywords” in the source code, and find there is only one instance in an <h3> tag. All the subjects/keywords follow this as a series of <a href> links with text. Unlike the date and title, the mark-up on these keywords do not provide a specific class or id, like “class=’keyword’” or id=”keyword”, that I can hook into. However, for each of these keywords, a title “Browse Works By Subject” has been assigned. To be certain this is a title unique to keywords, I search the entire document for this phrase and find that it is a title only used for keywords. So now I have all my hooks as follows:
- title: found in <div class=”record_title”>
- date: found in <div class=”record_date”>
- subjects: a.k.a. keywords, found in <a href> tags that have the title “Browse Works By Subject”
My Python code for retrieving those elements and storing them in Python dictionary called ‘doc_dict’ (declared earlier) looks like this:
# loop through each link in doc links to get data
for doc_link in doc_links:
doc_dict[doc_link] = {}
doc_dict[doc_link]['url'] = doc_link
doc_page = requests.get(doc_link)
doc_html = doc_page.text
doc_soup = BeautifulSoup (doc_html)
#title
doc_title_string = doc_soup.find("h3", attrs = {"class":"record_title"})
doc_title= doc_title_string.contents[0]
doc_dict[doc_link]['title'] = doc_title
#date
try:
doc_date_string = doc_soup.find("div", attrs = {"class":"record_date"})
doc_date= doc_date_string.contents[0]
except:
doc_date = "n.d."
doc_dict[doc_link]['date'] = doc_date
#subjects
doc_subject_strings = doc_soup.find_all("a", attrs = {"title":"Browse Works By Subject"})
temp_subjects = {}
# check if subjects
if doc_subject_strings:
for subject_string in doc_subject_strings:
subject = subject_string.contents[0]
subject_uri = subject_string.get('href')
temp_subjects[subject] = subject_uri
doc_dict[doc_link]['subjects'] = temp_subjects
Both names and descriptive terms can be found among the subjects. And if, for example, the name or term was found in the Getty vocabularies at the time the record was created, the Getty ID appears in the link. For example, “Ai Wei Wei” as a subject terms links on artasiamerica to “http://artasiamerica.org/search/by/subjects/500125586”. The trailing number equates with the ULAN ID for Ai Wei Wei “http://vocab.getty.edu/ulan/500125586”. But not all artist names appearing on artasiamerica had records on ULAN at the time, so it will be worth it to try to batch reconcile these names again. How to do this will the topic of a future post.
Resources and Recommendations
- Beautiful Soup Documentation
- SAMS Teach Yourself Python in 24 Hours by Katie Cunningham, 2nd Ed.
- And Pratt Institute’s School of Information has a great class called Programming for Cultural Heritage, currently taught by Matt Miller, where I first learned how to webscrape.